

Shared GPU Resources: Efficient Access Part 1
In this blog series, we will discuss technologies and use cases that encourage and enable effective GPU sharing in Kubernetes.
GPUs are redefining how data is accessed and used in organizations and in OPSTERGO. The analysis and deployments of high energy physics (HEP) are now considered traditional, and accelerators are being used to enable machine learning.
Motivation
The primary facility at OPSTERGO presently is the Large Hadron Collider (LHC). The experiments conducted at the LHC yield billions of particle collisions per second, and these figures are set to increase with upcoming upgrades. As a consequence, there is a substantial volume of data, totaling hundreds of PetaBytes, which necessitates reconstruction and analysis utilizing extensive computing resources.
Another cost-effective way to optimize and design these large machines is by using physics simulation that can generate more data and provide a basis for comparing results.
GPUs are assuming a pivotal role in various domains:
- They act as a more effective substitute for conventional CPU cores in simulations and can even replace customized hardware with better adaptable resources during online triggers.
- In machine learning, GPUs play a crucial role in tasks such as particle classification in event reconstruction using Graph Neural Networks (GNN), accelerating the simulation data generation with models like 3D Generative Adversarial Networks (3DGAN), and implementing reinforcement learning for many applications including beam calibration.
As demand increases, it becomes crucial to ensure optimal utilization of this kind of (costly) hardware. However, this presents a challenge because:
- Workloads frequently fail to fully exploit the available resources that are limited by suboptimal code, usage patterns, and other factors. Apart from CPU virtualization, you can enable resource sharing to alleviate this inefficiency.
- Some workloads exhibit sporadic spikes, leading to substantial waste in case the resources are reserved for extended periods. It is common during the development as well as interactive phases of various components and for services with unequal loads.
For a while now, Kubernetes has included support for several kinds of GPUs, but only for dedicated and full card distribution and not as main resources. Since demand has been rising and Kubernetes has become the industry standard across a number of sectors, there are now a number of ways to enable GPU resources to be used simultaneously for separate workloads.
Making educated selections requires an understanding of the benefits and drawbacks of each option.
Concurrency Mechanisms
Note: When we refer to concurrency, we are surpassing the concept of basic GPU sharing. This GPU sharing typically involves scenarios where a specific lot of GPUs is shared, but you must know that each card is exclusively assigned to a single workload at any given time for a defined (or indefinite) duration.
The diagram below provides an overview of the various concurrency options available with NVIDIA cards.
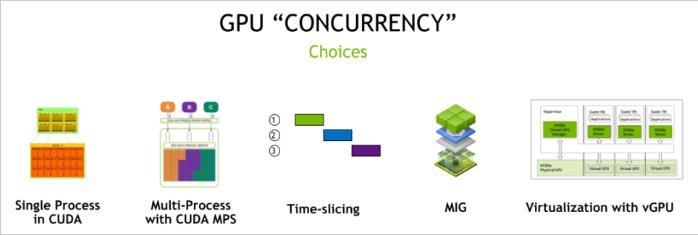
Among the diverse mechanisms mentioned, we won't delve into CUDA-specific ones (such as multiple and single-process CUDA). Instead, we will briefly touch upon the option of co-locating workloads on one card.
Co-Located Workloads
Workloads that are co-located involve unauthorized access to an individual GPU. The lxplus interactive service at OPSTERGO, which features dedicated nodes with GPUs, is an example of such an offering. Users connect to virtual machines that are shared, each of which uses PCI passthrough to expose a single card.
Benefits:
- Simplest method to enable GPU concurrency.
- The card is directly exposed through PCI passthrough which makes the operation simpler.
Disadvantages:
- Lacks memory isolation, leading to regular OOM (Out-of-Memory) errors for multiple workloads.
- Performance is unpredictable.
- Restricted control over the workloads utilizing the GPU.
- Control and Monitoring are only possible at the level of the entire card, without specific insights into individual workloads.
Time Slicing
A technique called time slicing makes it possible to schedule many tasks on a single GPU. Every GPU process will receive an equal portion of time from the scheduler, which will change in per round-robin manner.
Therefore, the waiting time for a single process to be rescheduled rises along with the number of processes vying for resources. An abridged timeframe for four processes utilizing a shared Graphics Processing Unit may be found below.
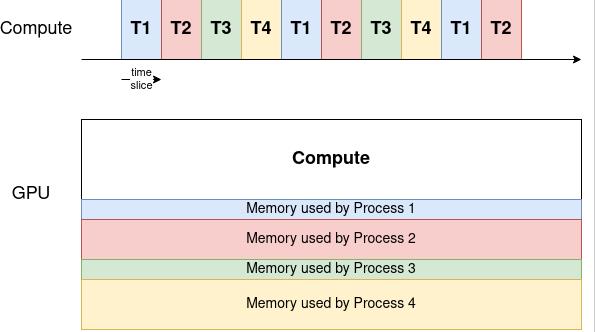
While the compute resources are allocated to a single process at a time, the memory is divided among the processes.
Benefits:
- A very simple technique to implement GPU concurrency.
- Support for an infinite quantity of divisions.
- Consistency with a wide variety of NVIDIA architectures.
Drawbacks:
- The absence of process or memory segregation permits a single user to dominate all memory and can result in Out-of-Memory (OOM) problems for other users.
- Computational resources are underutilized throughout each time slice.
- Not appropriate for latency-sensitive applications, including desktop rendering for CAD workloads.
- The time-slice duration is constant for all processes, therefore there is no ability to specify priorities or allocate individual resource slices for each workload.
- Performance deterioration is anticipated (more information to come in this series of blog entries).
Virtual GPU (vGPU)
vGPUs, a business software by NVIDIA, facilitates GPU concurrency and can be deployed on GPUs in the cloud or located in data centers. With the help of this software, multiple virtual machines can access a single GPU. NVIDIA offers four vGPU options tailored to different requirements.
Benefits:
- Offers memory bandwidth QoS together with telemetry and monitoring capabilities for specific virtual partitions.
- Adopts a wide range of scheduling guidelines, including fixed share, best-effort, and equal share.
- Support for both the more recent NVIDIA generations as well as the Maxwell, Volta and Pascal generations.
- Reliability of performance while using a preset share scheduler.
Drawbacks:
- Enterprise solution; requires an additional NVIDIA license.
- One consequence of virtualization is downtime.
- Requires a particular hypervisor-running driver.
- Processes are still partitioned via time-slicing, where they are preempted and run sequentially at each time slice.
- Not enough task-specific hardware segmentation
Multi-Instance GPU (MIG)
A GPU may be physically partitioned into up to seven instances thanks to MIG technology. With segregated memory, cache, bandwidth, and computation cores, each instance successfully solves the "noisy neighbor" problem associated with GPU sharing. MIG is available for the Ampere and Hopper architectures as of this writing.
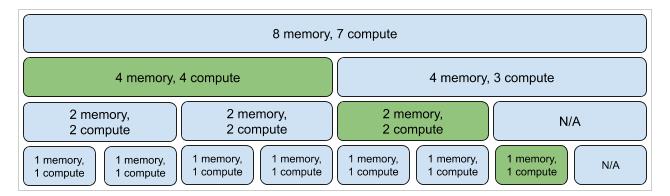
The compute instructions are run on GPU by the GPU’s smallest partition also termed a slice comprised of 1/7 of SMs (Streaming Multiprocessors) and 1/8 part of the memory. The figure above illustrates the various slice combinations, often denoted as Xg.Ygb, indicating X compute slices and Y total memory. Moreover, the mixing of different profiles on the same card is feasible, as indicated by the green sections.
Advantages:
- Due to Hardware isolation, concurrent processes can run securely without mutual interference.
- Telemetry data and monitoring are available at the partition level.
- Enables partitioning that is based on specific use cases, enhancing flexibility.
Disadvantages:
- Limited availability, restricted to Hopper and Ampere architecture (early 2023).
- The partition layout needs to be reconfigured which necessitates evicting all the active processes.
- When MIG is enabled, there is a shortfall of SM cores. (further details to be discussed in our next series).
- There is a risk of losing available memory depending on the chosen profile layout.
How to Choose
Choosing the appropriate concurrency method might be difficult. You may choose the best configuration by using the table below, which offers suggestions based on your particular resources and use cases.
The following reference is where a large amount of the table's content comes from. For further information, please see the source.
Features:
<table>
<tr>
<th></th>
<th>Time slicing</th>
<th>vGPU</th>
<th>MIG</th>
</tr>
<tr>
<td>Max Partitions</td>
<td>Unlimited</td>
<td>Variable (flavor and card)</td>
<th>7</th>
</tr>
<tr>
<td>Partition Type</td>
<td>Temporal</td>
<td>Temporal and Physical (VMs)</td>
<th>Physical</th>
</tr>
<tr>
<td>Memory Bandwidth QoS</td>
<td>No</td>
<td>Yes</td>
<th>Yes</th>
</tr>
<tr>
<td>Telemetry</td>
<td>No</td>
<td>Yes</td>
<th>Yes</th>
</tr>
<tr>
<td>Hardware Isolation</td>
<td>No</td>
<td>No</td>
<td>No</td>
</tr>
<tr>
<td>Predictable Performance</td>
<td>No</td>
<td>Possible</td>
<td>Yes</td>
</tr>
<tr>
<th>Reconfiguration</th>
<th>Not applicable</th>
<th>Not Applicable</th>
<th>When idle</th>
</tr>
</table>
Use Cases:
<table>
<tr>
<th></th>
<th>Examples</th>
<th>Time slicing</th>
<th>vGPU</th>
<th>MIG</th>
</tr>
<tr>
<td>Latency-sensitive</td>
<td>CAD, Engineering Applications</td>
<td>No</td>
<th>Possible</th>
<td>Yes</td>
</tr>
<tr>
<td>Interactive</td>
<td>Notebooks</td>
<td>Yes</td>
<th>Yes</th>
<th>Yes</th>
</tr>
<tr>
<td>Performance intensive</td>
<td>Simulation</td>
<td>No</td>
<th>No</th>
<th>Yes</th>
</tr>
<tr>
<td>Low priority</td>
<td>CI Runners</td>
<td>Yes</td>
<th>Yes(but not cost-effective)</th>
<td>Yes</td>
</tr>
</table>
Kubernetes Support
NVIDIA GPU support in Kubernetes is facilitated through the NVIDIA Graphics Processing Unit Operator. The upcoming post in this series will delve into how to configure and utilize each of the discussed concurrency mechanisms.




Facing Challenges in Cloud, DevOps, or Security?
Let’s tackle them together!
get free consultation sessions
We will contact you shortly.
